… my doubts crept in, since the Mind and the Quill may Race along happily enough during Composition of the Work, but when one stops to copy out one's Words, the very Slowness and Dullness of the Task makes one doubt all.
Erica Jong, Fanny, being the True History of the Adventures of Fanny Hackabout-Jones, 1980.
The thesis presented is that multi-column partitioning is a suitable method of minimising wasted work done on Management Information Service (MIS) range queries run against a large Transaction Processing (TP) database.
The aim is to reduce the search space so that full file scans are not needed, since these are extremely expensive (the work pertains to databases containing many tens or hundreds of Gigabytes of data).
Indexing is not a suitable method for the query types under discussion, and there are fundamental limitations to multi-column file partitioning methods. This chapter outlines the issues.
Databases and database systems are now an integral part of modern society, and their use is becoming ever more widespread. Databases range in size from tiny data banks containing, say, data for a personal address book to large scale industrial systems which store hundreds or thousands of Gigabytes of data.
On-line Transaction Processing (OLTP) systems are database systems which require rapid response to user queries (henceforth called transactions). Examples of such systems are airline reservation systems, electronic point of sale systems and automatic teller machines.
The work in this thesis deals with industrial OLTP systems where the database size is upwards of 10 Gigabytes. The application domain is banking, and the relational model is used to describe the data. In this environment there is much information that could be useful to the business if it could be extracted from the OLTP data. For example, the advertising of a new credit card might be targeted to people who fulfil some criteria based on say frequency of use of their current card, salary and average monthly spending on the current card. This type of query is called an MIS (Management Information System) query. However, there are problems with accessing the huge volumes of data involved in this type of query.
Over the years, various hardware and software database machines have been designed and built in order to overcome the problems involved in data access. It is generally accepted that multi-processor database machines are the most promising way forward. A notable commercial success is the Teradata DBC/1012 [REED90]; its limitations are discussed later. The work contained in this thesis is based on, but not limited to, the architecture of one particular shared-nothing database machine, IDIOMS [KERR91a] (see chapter 3).
Numerous methods for reducing the workload of data access have been devised. An index is needed for the OLTP transactions we are considering, whereas for the MIS queries multi-dimensional data partitioning is appropriate. There are costs associated with partitioning which affect OLTP transactions, so the trade-offs have to be quantified.
The overall problem to be solved can be stated formally as follows:
Given a set of simple OLTP (Online Transaction Processing) transactions and a set of MIS (Management Information System) queries composed of range and point queries in one or more dimensions, minimise the overall OLTP and MIS workload with the constraint that OLTP is not excessively hindered by the partitioning. This requires determination of
a) which column(s) to partition to create a multi-dimensional file structure
b) the number of partitions needed in each partitioning dimension of that file structure.
The main assumptions made are:
Section 1.2 presents a general overview of the work and concludes with a list of further assumptions made. Section 1.3 outlines the organisation of this document, and section 1.4 discusses the problem of combined OLTP/MIS access in more detail.
"Several research issues remain unsolved including… techniques for mixing ad hoc queries with Online Transaction Processing without seriously limiting transaction throughput" [DEWI92].
The work presented here is an investigation of multi-column (i.e. multi-dimensional) partitioning in combined multi-processor OLTP/MIS systems which use a single data set based on the relational model. The aim is to reduce MIS workload of large queries without causing 'excessive' penalty to OLTP transactions.
The term MIS is used to include 'data mining' applications [ONEI91] where large portions of a database may be scanned in order to extract, for example, statistical information. MIS queries access large fractions of the database, and hence an index is not appropriate (even apart from the problem that index overheads are extremely high). OLTP is 'mission critical', and so has priority over MIS. OLTP queries are 'single hit' and require rapid access to records, therefore an index is needed. Individual OLTP transaction times as well as overall throughput are important. The work presented here investigates maximising the total (i.e. MIS plus OLTP) workload reduction by partitioning, with the constraint that the OLTP penalty of partitioning does not exceed some given limit.
Treating all keys equally in terms of partitioning is not the best approach in terms of total workload minimisation since on some columns the partitioning penalty outweighs possible savings. A trivial example is that if an MIS query requires all the data, no strategy can reduce the total workload. Hence we need not only to determine which columns to partition on, but also to derive metrics for the number of partitions for each partitioning dimension.
This thesis looks at minimising wasted work of MIS range queries. For example, a 0.1 selectivity MIS query which accesses all the file (because there is no partitioning) wastes a vast amount (0.9) of effort. With two partitions, and assuming the required data is wholly contained within one partition, the wasted work drops dramatically to 0.4. The question arises as to what a suitable level of partitioning might be for a set of MIS queries ignoring at this stage any overheads.
Partitioning does have costs, and where the number of partitioned columns is low, this cost is mainly due to migrations between partitions of each column. In order to find the best number of partitions for each column, the cost of migration must be related to the MIS workload savings. Where many columns are partitioned the cost of the access mechanism is prohibitive (e.g. a Grid File [NIEV84] of 10 columns, each with 10 partitions, requires a grid array containing 1010 pointers to partitions).
It is possible that partitioning on a column that would lead to high overall savings also would lead to a high penalty for OLTP in terms of migration costs. This would not be allowed, since OLTP throughput must not be compromised; hence an upper bound has to be put on OLTP partition cost.
The work focuses on columns with large domains, but the concepts are applicable to all sizes of domain. Determination of the optimum number of partitions for each column is discussed. For a given set of MIS queries which have single clause predicates only, it is possible to derive an optimal partitioning strategy in linear time. With compound clauses the computation is not linear, and therefore it is not practical except where the number of columns in the file is small. A heuristic solution is proposed.
One problem that arises is the estimation of the number of partitions accessed by range queries. The formula presented by Eastman [EAST87] for pages accessed by range queries does not translate well when it is used for the number of partitions accessed where the number of partitions is small. A new formula estimating the average number of partitions accessed by range queries is derived. One implication of Eastman's formula is that the size of a query does not affect the scan time savings that can be made by increasing the number of partitions. This is not true when the number of partitions is small. The new formula accounts for this.
Further important assumptions about the work are listed below:
Chapters 2 and 3 are the review stage of this thesis. Chapter 2 deals with concepts of partitioning, placement and retrieval, and relates these to the problem of accessing large amounts of data for MIS purposes. Chapter 3 puts IDIOMS into context, and discusses the logical and architectural similarities between other database machines. The work presented in this thesis is not specific to IDIOMS, although it stems from problems that IDIOMS was designed to solve, so chapter 3 discusses the problem of concurrent OLTP/MIS access and MIS workload reduction in terms of the IDIOMS architecture.
Correctly estimating the number of partitions accessed by range queries in range partitioned files when the number of partitions is small is discussed in chapter 4, and a new formula is presented. Implications of this formula and Eastman's formula are discussed.
A cost model relating OLTP cost penalty of partitioning to MIS scan time savings of such partitioning is devised in chapter 5, followed by a discussion of MIS partitioning for the case where OLTP costs are ignored. Since costs are discussed in abstract terms, the next chapter uses a realistic example to show how the model would be used in practice.
Finally, of course, overall conclusions are drawn, limitations are discussed, and further research is proposed in chapter 7.
The remainder of this chapter defines the problem in more detail.
Typically, the OLTP side of the system is mission-critical, and rigid performance parameters must be adhered to. For example, the Halifax Building Society state, "Positioned through the walls of branches, Cardcash machines provide a 21-hour service from 5 am to 2 am, 365 days a year" [HALI93]. MIS information extracted directly from OLTP data is becoming increasingly important, and organisations are continually striving to increase the availability of this [ONEI91].
Oates presents some excellent examples of typical MIS queries [OATE91], which are shown below.
The MIS queries which this work is concerned with are of the SQL [ISO89] form
SELECT columns
FROM table
WHERE condition
Each clause of the condition predicate can be considered in isolation due to the hierarchical nature of the partitioning.
For example, consider the partitioning shown in figure 3.3 on page 35. If the condition is GENDER = 'FEMALE', then 9 partitions must be accessed. If the condition is AGE BETWEEN (30 AND 40), then 6 partitions are accessed. If the conditions are combined, then only those three partitions satisfying both clauses are accessed. Note that the condition clause says nothing of whether or not the tuples satisfying a condition are physically returned from the database.
In general, the queries are range queries (i.e. the required data is within a given range of values). If more than one column appears in the condition (predicate) clause, then the query is known as an orthogonal range query (ORQ). The work does not investigate other types of query (e.g. point [footnote1], partial match), but of course, these may be posed.
Banking OLTP systems which use such things as automated teller machines (ATM) and point of sale (POS) terminals are highly dynamic - the ratio of updates to reads is high. The typical OLTP query is single-hit (only one record is required) on the basis of the primary key (e.g. account number, customer number). Access must be rapid, preferably instantaneous as far as user perception is concerned, so there is usually a dense index on the primary key. MIS systems, on the other hand, are static in that (OLTP) data is read, but generally never updated by the MIS queries. Furthermore, multi-attribute retrieval over a range of values (i.e. orthogonal range query) is often required.
Research into data storage and retrieval is prolific, and many methods to aid multi-dimensional access have been proposed, for example the Grid File [NIEV84], multi-dimensional clustering [LIOU77], the hB-tree [LOME90]. However, no strategy that deals with the conflicting requirements of combined OLTP/MIS systems has been found.
Nievergelt et al., in their seminal paper on the Grid File [NIEV84] state, "all known searching techniques appear to fall into one of two broad categories: those that organize the specific set of data to be stored, and those that organize the embedding space from which the data is drawn" (emphasis in original). Indices are of the first type, and the Grid File and range partitioning of the second.
Any indexing strategy that is chosen will result in storage costs and update costs, in addition to the access cost of the index itself. For any column that is indexed, any update due to a transaction will also require an index update. Thus in an environment where OLTP takes precedence it is not viable to index columns for MIS purposes that are more than moderately updated, because the costs will become prohibitive. Furthermore, the storage requirement of having many indices becomes a major part of the total storage requirement. Multi-attribute indices are no solution, as the problem of index update remains.
Indexing does not necessarily improve retrieval time. If no queries use the indexed column, then the index is redundant. If all values are required, then the whole file (or partition) must be read. Index selection therefore requires, amongst other things, knowledge of the queries posed. Additionally indices are not particularly useful without some form of data clustering even for small range queries, because a random distribution of data would lead to most data pages being accessed - see for example [EAST92]. Thus one design decision of IDIOMS was that no indices whatsoever are used for MIS purposes [footnote 2].
Copeland et al. suggest that access frequency to columns ('column heat') can be used to determine which column(s) should be indexed [COPE88]. With similar reasoning the access frequency to columns determines which columns are to be partitioned for MIS. However, knowledge of the access frequency in itself is not sufficient, for example, if the selectivity [footnote 3] of a query is 1 (i.e. all records accessed), then no amount of partitioning will change the total amount of work that needs to be done to retrieve that data.
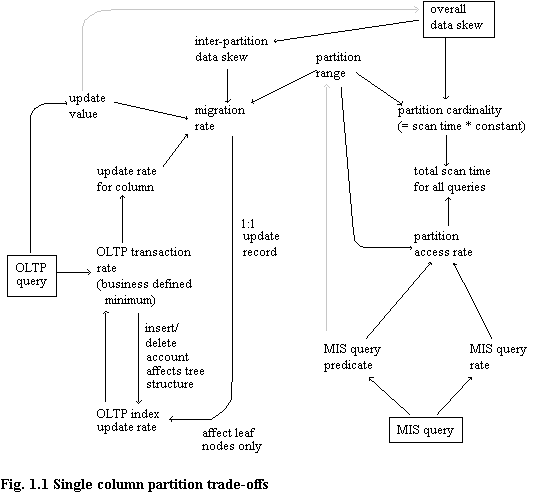
A number of data partitioning strategies exist, for example, the Grid File [NIEV84], DYOP [OZKA85], hash-based [AHO79], and horizontal range partitioning [DEWI90b]. They all suffer from the same fundamental limitation, namely the requirement of data migration. Placement of data is based directly or indirectly on column value(s), so whenever the value changes there is the possibility that the location of data should change. For any given update, the smaller the partition the greater the likelihood that migration will be necessary. Unlike indexing methods where a change in a data valued results in a change to the index, an update does not automatically result in the necessity for migration, but rather is a function of the partition range and update value. This is examined in chapter 5, the cost model.
Note that whatever kind of structure is used to organise the data space, there will be this migration cost. It matters not whether there is a static mapping between the data space and the disc, or whether there is a dynamic mapping as with the Grid File. At a given time, for a given set of physical partitions there is a migration rate between partitions which is dependent solely upon the semantics of the database. To reiterate, "A change in the value of any attribute may result in its being moved from one partition to another…" [EAST87]. Recall that because we need fast OLTP response there is a dense index on OLTP access keys. This leads to another problem - the cost of migration is a compound cost, namely the cost of insertion and deletion of a record, plus an OLTP index update on this record. Unfortunately MIS partitioning leads to OLTP overheads, as shown in figure 1.1.
Ghandeharizadeh and DeWitt [GHAN90a] briefly discuss query selectivity and its effects on range partitioning in the context of a comparison with indexed methods of data retrieval on the Gamma database machine. They use average throughput (queries/second) as a measure of evaluation. This masks the two factors involved; the power of the machine (which is based on the number of processors), and the power of the partitioning strategy, which is determined by the relationship between partition size and query size. (This is in contrast to the more usual perspective of an efficiency based approach).
The power of a machine is its rate of work. In our case, for MIS this equates to its speedup (over some reference system). Now ideally, as far as MIS data access is concerned, speedup (increase in power) is linearly dependent on the number of storage discs and their associated processors - twice as many discs and associated processors result in a doubling of the overall scan rate (i.e. half scan time). Of course, in practice, for any machine speedup is not linear with the number of discs and processors, but that is not germane to this discussion.
On the other hand, the power of the partitioning strategy is affected by the size of partitions. In the ideal case, where efficiency [footnote 4] is 100% (i.e. no unwanted tuples retrieved), and where data is evenly distributed, the partitioning power is equivalent to 1/query size. For example, if the query size = 0.125 with respect to the size of the domain, then the power of the partitioning strategy = 8; instead of scanning a unit database to resolve a query, only 1/8 needs to be scanned. Thus, in the best case, 8 times as many queries can be solved per unit scan time. The power of this partitioning is not dependent upon the absolute size of the database, what is important is the relative sizes of the partitions and queries. Whether this partitioning takes place in a single processor or multi-processor environment is immaterial. What the multi-processor system does is to allow a greater throughput. The work presented here focuses on total workload reduction, rather than attempting to increase throughput by means of increasing computational resource. One of the fundamental questions addressed is, "how big should partitions be?"
Eastman, amongst others, has studied optimum bucket size for multi-attribute retrieval in range partitioned files [EAST87]. Her analysis is based on the relative costs of bucket retrieval and record examination, and, "if disk storage is used, this [cost of retrieval] can usually be regarded as equivalent to a disk access… Furthermore, the cost of accessing a bucket is not completely independent of the bucket size." All the other similar analyses investigated equate buckets with disc pages. In IDIOMS page size is determined by OLTP queries, and the data they manipulate. Typically, it is between 512 bytes and 4K bytes. The partitioning to aid MIS is such that many thousands of pages are contained in each MIS partition, and thus the cost of accessing a partition (cf. Eastman's bucket) is totally dependent on the partition size. Rather than minimising the sum of bucket retrieval costs and record examination costs, which is Eastman's aim, the goal is to minimise (as far as is practical) partition retrieval costs with respect to the cost of partitioning (i.e. migration and index update costs).
Finally, it is worth stressing that the methods presented here address practical problems in large commercial databases. No attempt is being made to find a theoretical optimum solution.
"I shall now dismiss our impatient reader from any further attendance at the porch, and, having duly prepared his mind by a preliminary discourse, shall gladly introduce him to the sublime mysteries that ensue." - Jonathan Swift.
footnote 2. The White Cross family of database systems released late in 1992 also does not require indices for MIS queries [HOLL92].
footnote 3. Selectivity is used to mean the fraction of records satisfying a query. Later the term query size is used to mean the fraction of records satisfying a condition in a single dimension. The terms are synonymous in the one-dimensional case.
footnote 4. Precision in Nievergelt's terminology [NIEV84].